

Του Παναγιώτη Παπαντωνάκη
Στα πλαίσια του Google Summer of Code 2019 αναπτύχθηκε ένα πρόγραμμα Windows για την εξαγωγή γλωσσικών χαρακτηριστικών από αρχεία κειμένου με τίτλο Development of a Tool for Extracting Quantitative Text Profiles.
Περιγραφή
Ένα σημαντικό μέρος των μεγάλων δεδομένων (big data), που διακινείται καθημερινά στο διαδίκτυο, αποτελείται από κείμενα. Από απλά tweets και κοινοποιήσεις στο facebook έως άρθρα, ειδήσεις και επιστημονικά περιοδικά, τα κείμενα υπάρχουν παντού και αποθηκεύουν τεράστια πληροφορία. Την πληροφορία αυτή την αξιοποιεί, για την εξαγωγή διάφορων γλωσσολογικών χαρακτηριστικών, ένας συγκεκριμένος επιστημονικός κλάδος (Υπολογιστική Γλωσσολογία), αναλύοντάς την με ειδικά προγραμματιστικά πακέτα και αλγόριθμους.
Δυστυχώς, κάθε πακέτο, που υπάρχει διαθέσιμο, δεν συγκεντρώνει όλους τους επιθυμητούς γλωσσολογικούς δείκτες και, επιπλέον, δεν είναι πολύ φιλικό στη χρήση από κάποιον χωρίς ιδιαίτερες προγραμματιστικές γνώσεις, όπως οι άμεσα ενδιαφερόμενοι ερευνητές.
Στόχος της εργασίας είναι να διευκολύνει την έρευνα στην υπολογιστική γλωσσολογία, δημιουργώντας ένα πρόγραμμα υπολογιστή με γραφικό περιβάλλον (GUI), που θα είναι φιλικό στο χρήστη, θα μπορεί να χρησιμοποιηθεί από άτομα χωρίς προγραμματιστικές γνώσεις και το οποίο θα επιτρέπει την ανάλυση αρχείων κειμένου ως προς τους πιο γνωστούς δείκτες, την προβολή και την εξαγωγή των αποτελεσμάτων. Το πρόγραμμα ενσωματώνει σε μια ενιαία πλατφόρμα ήδη υπάρχουσες, ετερογενείς βιβλιοθήκες και πακέτα και έχει μεγάλο βαθμό κλιμακωσιμότητας και επεκτασιμότητας, καθώς επιτρέπει την εισαγωγή αλγορίθμων από το χρήστη για επιπλέον ανάλυση των αρχείων, έτσι ώστε να προσαρμόζεται στις ανάγκες του.
Οργάνωση Εργασίας
Η εργασία χωρίστηκε σε 2 μέρη:
- Δημιουργία των scripts που υλοποιούν την ανάλυση του κειμένου
Σε αυτό το μέρος, αρχικά, ελέγχθηκαν οι υπάρχουσες βιβλιοθήκες ανάλυσης φυσικής γλώσσας, σε σχέση με την ποικιλία υλοποιημένων δεικτών, τις υποστηριζόμενες γλώσσες, την απόδοση καθώς και τη μεταξύ τους συμβατότητα. Οι βιβλιοθήκες που επιλέχθηκαν τελικά, είναι οι quanteda και koRpus, που συνιστούν πακέτα της R, μιας γλώσσας που είναι σχετικά γνωστή στο κυρίως κοινό που απευθύνεται η εφαρμογή.
Με τη χρήση διαφόρων συναρτήσεων τους, κατασκευάστηκαν τα 3 αρχεία, readability_indices.R, lexdiv_indices.R, misc_indices.R, που κάνουν ανάλυση ως προς την αναγνωσιμότητα, τη λεκτική ποικιλία και άλλους δείκτες, αντίστοιχα. Τα αρχεία αυτά παίρνουν ως είσοδο το φάκελο που είναι εγκατεστημένες οι βιβλιοθήκες της R, τα αρχεία που πρόκειται να αναλυθούν και τους δείκτες που θα υπολογιστούν και εξάγουν τα αποτελέσματά τους σε ένα json αρχείο.
- Ανάπτυξη του γραφικού περιβάλλοντος
Σε αυτό το μέρος, έπρεπε να παρθεί η πιο σημαντική σχεδιαστική επιλογή· το πρόγραμμα θα δούλευε τοπικά (desktop) ή σε ιστοσελίδα; Αφού συγκεντρώθηκαν και αξιολογήθηκαν τα θετικά κι αρνητικά για κάθε προσέγγιση, αποφασίστηκε το γραφικό περιβάλλον να αναπτυχθεί ως τοπικό πρόγραμμα, έτσι ώστε, μετά την εγκατάσταση και τη χρήση για πρώτη φορά (κατά την οποία γίνεται λήψη των απαραίτητων βιβλιοθηκών) να είναι διαθέσιμο offline και να επιτρέπει την επεξεργασία μεγάλου όγκου δεδομένων (που στην περίπτωση της ιστοσελίδας θα απαιτούσε πολύ γρήγορο upload από τη μεριά του χρήστη). Βέβαια, για να είναι πιο εύκολο ένα μελλοντικό μεταφορά της εφαρμογής online, χρησιμοποιήθηκε για την ανάπτυξή της το electron, μια πλατφόρμα που δίνει τη δυνατότητα μιας υβριδικής προσέγγισης. Ουσιαστικά, η πλατφόρμα αυτή, που λειτουργεί και σαν το back-end της εφαρμογής, επιτρέπει τη δημιουργία τοπικών προγραμμάτων με τη χρήση τεχνολογιών διαδικτυακού προγραμματισμού, όπως CSS, Javascript και HTML.
Στο front-end χρησιμοποιήθηκαν το ReactJS, που είναι μια βιβλιοθήκη της Javascript για την κατασκευή γραφικών περιβαλλόντων, που αποτελεί τη βάση τόσο για τη δομή όσο και για τη λειτουργικότητα της εφαρμογής. Για το styling του προγράμματος χρησιμοποιήθηκε η CSS βιβλιοθήκη Material-UI.
Τέλος, η εφαρμογή περιλαμβάνει και μια βάση δεδομένων. Μιας που τα δεδομένα μας είναι ημιδομημένα, μια NoSQL βάση, όπως η MongoDB, κρίθηκε ως η κατάλληλη για να χρησιμοποιηθεί.
Οδηγίες και Παράδειγμα χρήσης
Για τη χρήση της εφαρμογής είναι απαραίτητο να έχει το σύστημα εγκατεστημένα:
- τη γλώσσα R και
- τη βάση MongoDB (στη θήρα 27017, όπως ορίζεται εξαρχής στην εγκατάστασή της)
Η εγκατάσταση γίνεται πατώντας διπλό κλικ στο setup.exe.Έπειτα από την εγκατάσταση, για την πρώτη φορά που θα χρησιμοποιηθεί η εφαρμογή, είναι απαραίτητη η σύνδεση στο διαδίκτυο, για τη λήψη και εγκατάσταση των βιβλιοθηκών που εκτελούν την επεξεργασία των κειμένων. Αυτή είναι και η μόνη φορά που η εφαρμογή απαιτεί σύνδεση στο διαδίκτυο.
Αρχικά, ζητείται από το χρήστη η εισαγωγή του φακέλου που είναι εγκατεστημένη η R, καθώς και ενός φακέλου για την αποθήκευση των βιβλιοθηκών (αυτός μπορεί να είναι οποιοσδήποτε φάκελος). Οι επιλογές αυτές μπορούν να αλλάξουν πατώντας File > Settings.

Μετά από την αποθήκευση των επιλογών πραγματοποιείται η λήψη των βιβλιοθηκών. Το συνολικό μέγεθος είναι ~500MB, οπότε η διαδικασία μπορεί να κρατήσει λίγη ώρα. Στο τέλος θα εμφανιστεί κατάλληλο μήνυμα στην κονσόλα, που βρίσκεται στο κάτω μέρος της εφαρμογής.

Από αυτό το σημείο, η εφαρμογή είναι έτοιμη να χρησιμοποιηθεί. Στα αριστερά υπάρχει μια μπάρα πλοήγησης στα 3 βασικά παράθυρά της:
- το Input, στο οποίο ο χρήστης μπορεί να εισαγάγει, να επιλέξει ή να διαγράψει προς ανάλυση αρχεία
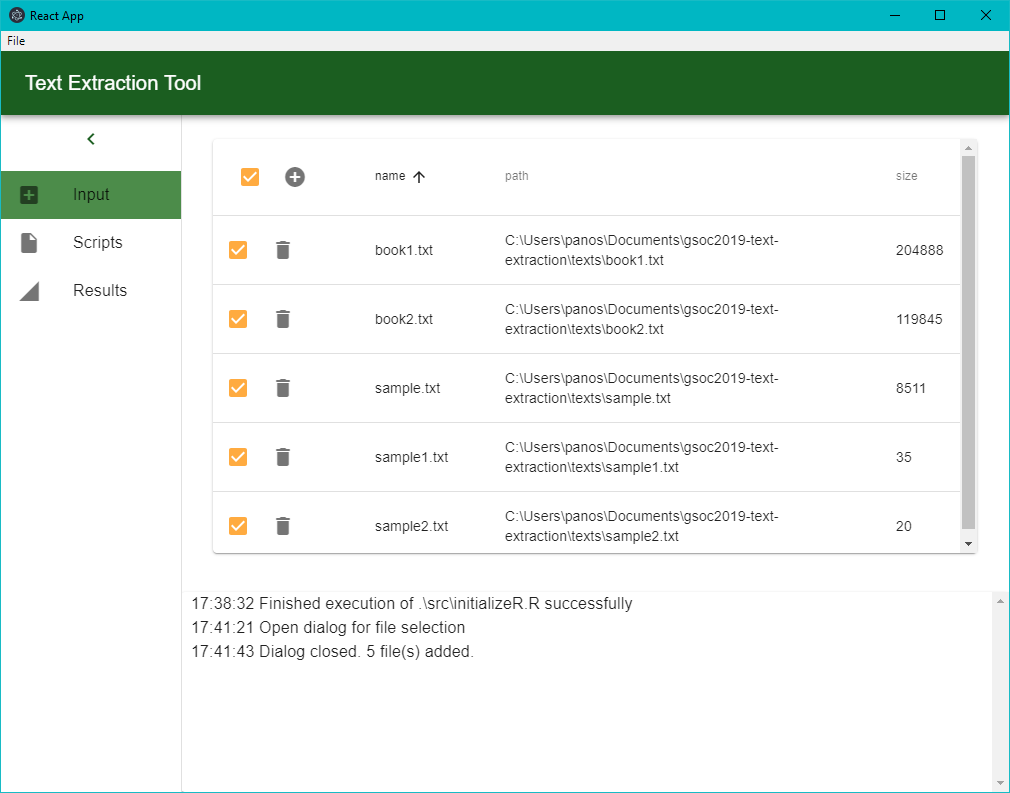
- το Scripts, στο οποίο γίνεται η επιλογή των δεικτών που πρόκειται να υπολογιστούν. Οι δείκτες μπορεί να ανήκουν είτε στους βασικούς (built-in)
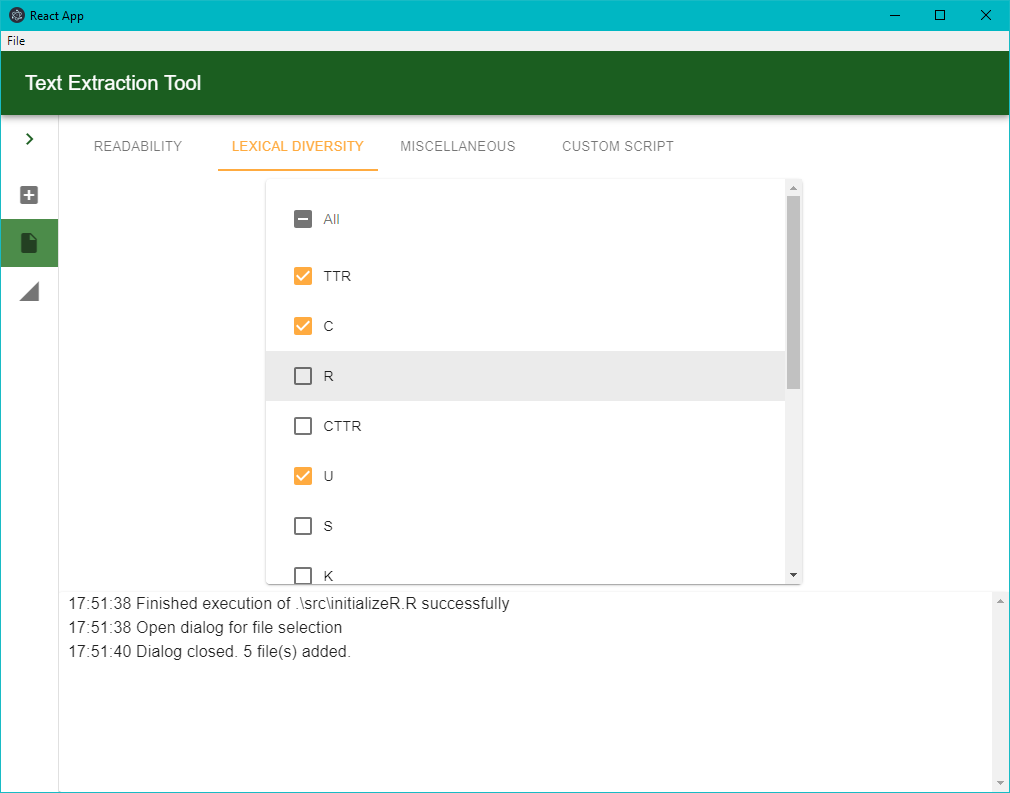
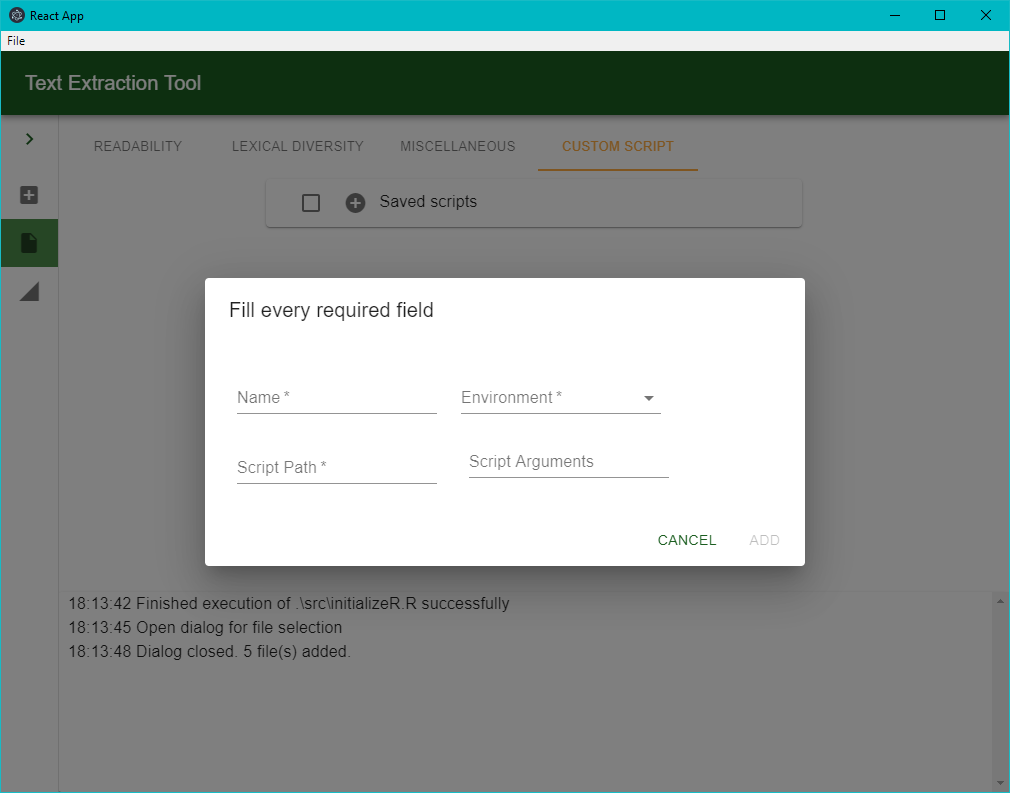
είτε να δίνονται από το χρήστη, μέσα από την καρτέλα Custom Script. Σε αυτήν, ο χρήστης μπορεί να εισαγάγει ένα δικό του script (όνομα, path, περιβάλλον εκτέλεσης, ίσως script arguments) για να εκτελεστεί μαζί με τα υπόλοιπα
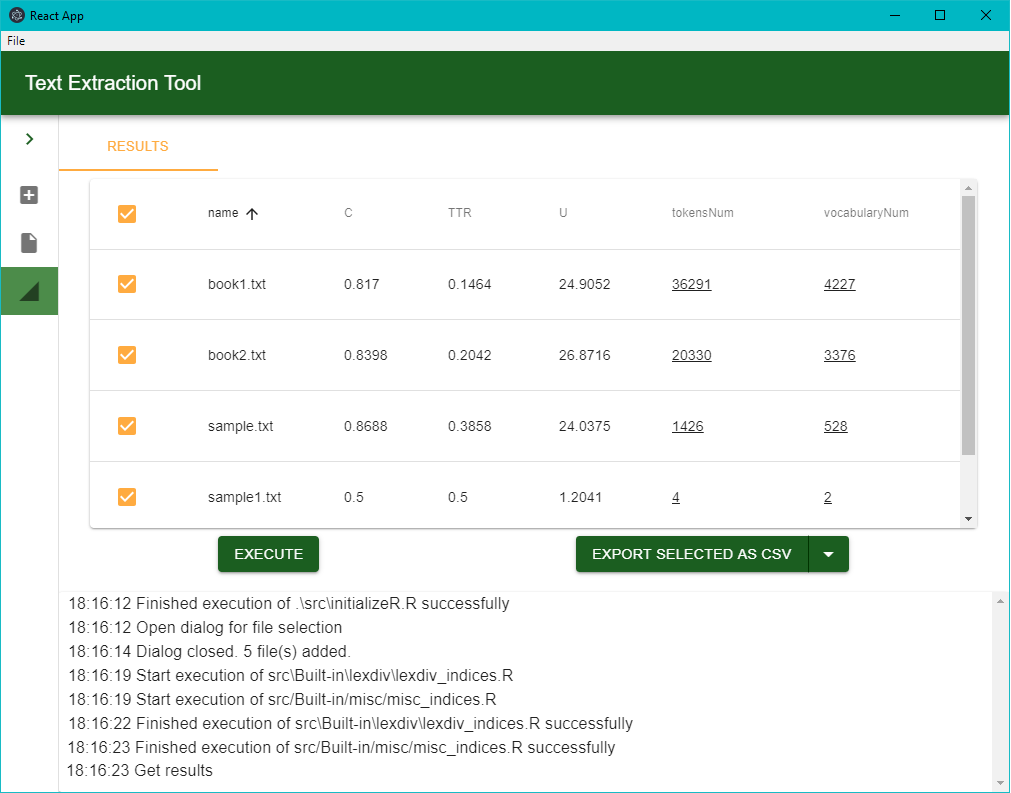
- το Results, στο οποίο γίνεται η εκτέλεση των scripts και η προβολή και εξαγωγή των αποτελεσμάτων σε μορφή json, text ή csv
Επόμενα βήματα
Το πρόγραμμα μέσα στο τρίμηνο του Google Summer of Code ξεκίνησε από το μηδέν και έφτασε σε επαρκές επίπεδο λειτουργικότητας, ώστε να μπορεί να θεωρηθεί alpha version. Βεβαίως, υπάρχουν ακόμα πολλά που μπορούν να γίνουν, κάποια από τα οποία περιγράφονται εδώ. Το τελικό παραδοτέο περιλαμβάνει links και πληροφορίες σχετικά με το έργο.