

Περιγραφή
Στη σημερινή εποχή, η επικοινωνία μέσω email είναι ένα καθημερινό φαινόμενο, το οποίο απαιτεί αρκετό χρόνο, ειδικά από ανθρώπους που δεν είναι «εκπαιδευμένοι» στην πληκτρολόγηση. Έτσι, μια υπηρεσία όπου ο χρήστης θα εκφωνεί το email του αντί να το γράφει θα ήταν πολύ χρήσιμη. Η υλοποίηση, όμως, ενός τέτοιου open-source συστήματος για τα Ελληνικά δεν είναι εύκολη. Η εκπαίδευση ενός συστήματος αναγνώρισης φωνής (Εικόνα 1) απαιτεί ένα πολύ μεγάλο Ελληνικό φωνητικό dataset, το οποίο πρέπει να αποτελείται από κείμενα μαζί με τις ηχογραφήσεις του. Τέτοια ανοιχτά datasets για Ελληνικά δεν υπάρχουν διαθέσιμα, με αποτέλεσμα το υπάρχον ακουστικό και γλωσσικό μοντέλο να έχει χαμηλή απόδοση.
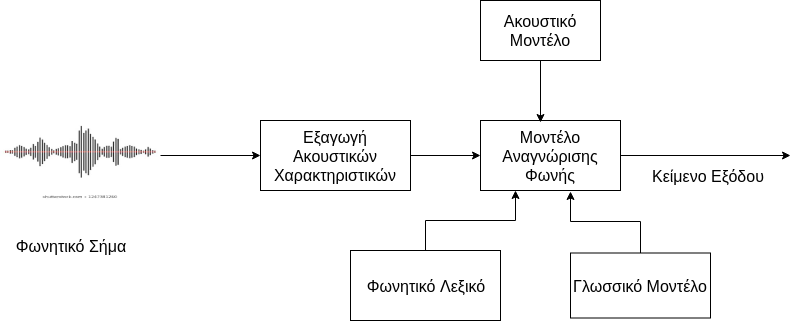
Λεζάντα: 1. Τυπική διαδικασία εκπαίδευσης συστήματος μετατροπής ομιλίας σε κείμενο
Λύση
Σκοπός, του παρόντος project ήταν να υλοποιηθεί ένα σύστημα εκφώνησης email το οποίο να προσαρμόζει κάθε φορά το ακουστικό και το γλωσσικό μοντέλο στον χρήστη, ή με άλλα λόγια το σύστημα να «μαθαίνει» την προφορά και το λεξιλόγιο που συνήθως χρησιμοποιεί. Το ακουστικό μοντέλο προσαρμόζεται στη φωνή του μέσω της ηχογράφησης ορισμένων προτάσεων και το γλωσσικό μοντέλο προσαρμόζεται στον τρόπο γραφής του μέσω των ήδη σταλμένων email του. Ως τελικό βήμα, υπάρχει ένα σύστημα μετ-επεξεργασίας για την διόρθωση των όποιων σφαλμάτων. Όλα αυτά υλοποιήθηκαν σαν ξεχωριστά off-line εργαλεία (Tools στο Wiki) αλλά και ως τμήμα ενός ιστότοπου.
Το CMUSphinx είναι η κεντρική βιβλιοθήκη του project το οποίο παρέχει πολλά χρήσιμα εργαλεία για την αναγνώριση φωνής. Επίσης, βασικές βιβλιοθήκες είναι το srilm, spacy και nltk. Το υλοποιημένο σύστημα φαίνεται στο παρακάτω διάγραμμα (Εικόνα 2).
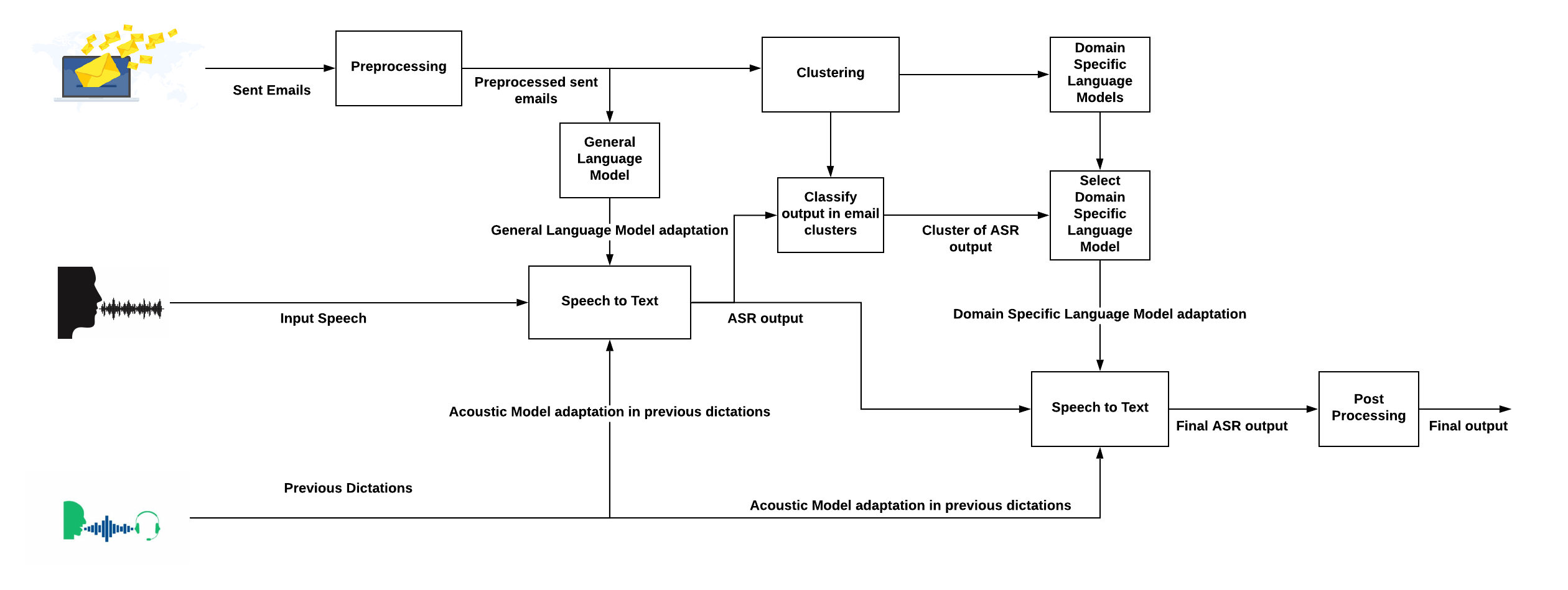
Λεζάντα: 2. Συνολικό προτεινόμενο σύστημα
Εργαλεία-Τεχνικές
Προσαρμογή γλωσσικού μοντέλου
- Φόρτωση email χρήστη: Με χρήση του Google API γίνεται φόρτωση των απεσταλμένων emails του χρήστη χωρίζονται σε προτάσεις και μετατρέπονται σε ελληνικές λέξεις μόνο με αλφαβητικούς χαρακτήρες.
- Ομαδοποίηση των email του χρήστη: Το επόμενο βήμα είναι η ομαδοποίηση των δεδομένων σε clusters. Για να χωρίσουμε τα emails σε νοηματικές ομάδες πρέπει να πάρουμε τις εξής αποφάσεις:
- Διανυσμασματική αναπαράσταση
Δοκιμάστηκαν διάφορα προ-εκπαιδευμένα word vectors με καλύτερα από πλευράς απόδοσης και ταχύτητας να είναι τα spacy vectors (τα οποία μάλιστα δημιουργήθηκαν σε περσινό πρότζεκτ του ΕΛΛΑΚ), ακολουθούμενα από μεθόδους όπως cbow και skipgram.
- Επιλογή αλγόριθμου clustering
Ο αλγόριθμος που επιλέχθηκε είναι ο k-means.
- Μέθοδος αυτόματης επιλογής αριθμού clusters
Για την αυτόματη επιλογή του αριθμού των τελικών ομάδων χρησιμοποιήθηκαν οι μέθοδοι silhouette και elbow με την πρώτη να βγάζει καλύτερα αποτελέσματα, καθώς είναι πιο επιρρεπής σε μικρό αριθμό clusters, κάτι το οποίο συνήθως είναι επιθυμητό (συνήθως τα email μας έχουν 2-4 θεματικές ενότητες).
- Επίπεδο clustering
Το clustering μπορεί να γίνει είτε στα emails είτε στις προτάσεις των emails. Προτιμήθηκε το πρώτο, καθώς η vector αναπαράσταση χειροτερεύει όσο μεγαλύτερη σε αριθμό λέξεων είναι η εκάστοτε φράση.
- Παρουσίαση των clusters στον τελικό χρήστη
Για κάθε cluster, επιλέγεται ως αντιπροσωπευτικό email το κοντινότερο στο κέντρο του και υπολογίζονται αντιπροσωπευτικά keywords, τα οποία αποτελούνται από λέξεις με την μεγαλύτερη tf-idf μετρική ανα cluster.
- Δημιουργία προσαρμοσμένων γλωσσικών μοντέλων: Το τελευταίο βήμα είναι η δημιουργία ενός γλωσσικού μοντέλου για κάθε cluster. Αυτό γίνεται με το εργαλείο SRILM. Αν κρατήσουμε απλά το γλωσσικό μοντέλο από τα email του cluster θα έχουμε πολλές άγνωστες λέξεις και η απόδοση δεν θα είναι καλή. Για τον λόγο αυτό, δημιουργήθηκε ένα μικτό γλωσσικό μοντέλο από το υπάρχον και το προσαρμοσμένο.
Προσαρμογή ακουστικού μοντέλου
- Ηχογράφηση εκφωνήσεων: Το πρώτο βήμα είναι η ηχογράφηση από τον χρήστη τυχαίων προτάσεων των email του. Όσες περισσότερες ηχογραφήσεις υπάρχουν, τόσο αυξάνεται η απόδοση του συστήματος.
- MLLR προσαρμογή: Η προσαρμογή του ακουστικού μοντέλου γίνεται με την MLLR μέθοδο, διότι προσφέρεται για περιπτώσεις όπου τα δεδομένα είναι σχετικά λίγα.
Σύστημα μετ-επεξεργασίας
- Εντοπισμός λανθασμένων λέξεων: Σύμφωνα με την μέθοδο αυτή, χρησιμοποιώντας το προσαρμοσμένο γλωσσικό μοντέλο, έχουμε μία πιθανότητας εμφάνισης για κάθε trigram. Αν αυτή είναι μικρότερη από ένα κατώφλι, το trigram θεωρείται λανθασμένο. Συνολικά, μία λέξη θεωρείται λανθασμένη αν συμμετέχει σε τουλάχιστον δυο λανθασμενα trigram.
- Διόρθωση λανθασμένων λέξεων: Στη συνέχεια, η λανθασμένη λέξη αντικαθίσταται από μια ακουστικά κοντινή της που υπάρχει στα email του χρήστη. Χρησιμοποιήθηκαν διάφορες αποστάσεις, όπως απόσταση POS tags, σημασιολογική και Levehnstein, χωρίς όμως να έχουμε καλά αποτελέσματα. Να σημειωθεί ότι το κομμάτι αυτό δεν πρόλαβε να ενταχθεί στην δικτυακή διεπαφή.
Αποτελέσματα
Σε περιπτώσεις όπου τα email του χρήστη είναι καλά δομημένα και σχετικά πολλά, τα αποτελέσματα είναι πολύ καλά. Το evaluation σε ένα αντιπροσωπευτικό dataset παρουσιάζεται εδώ.
Future Work
Ο όγκος του project οδήγησε σε πολλές πιθανές επεκτάσεις, που μπορούν να χωριστούν σε 3 κατηγορίες:
- Επέκταση της χρήσης του συστήματος (άλλοι πάροχοι email ή άλλες chat εφαρμογές).
- Βελτίωση της απόδοσης του μοντέλου με άλλες μεθόδους NLP.
- Βελτίωση του gui και διόρθωση πιθανών σφαλμάτων, τα οποία μπορεί να υπάρχουν εξαιτίας του περιορισμένου χρόνου.Πολλά από αυτά έχουν ήδη σημειωθεί εδώ.
Χρήσιμοι σύνδεσμοι
Για περισσότερες πληροφορίες για το project, μπορείτε να επισκεφτείτε τα παρακάτω:
Άτομα
- Google Summer of Code 2019 Student: Παναγιώτης Αντωνιάδης (PanosAntoniadis)
- Mentor: Αντρέας Συμεωνίδης (asymeon)
- Mentor: Μάνος Τσαρδούλιας (etsardou)